Oryx 推荐系统初体验
Summary
Oryx 的前身叫 Myrrix,后来被 Cloudera 收购改了这个名字。值得一提的是 Oryx 的维护者就是 Mahout 的主要贡献者——Sean Owen
Oryx开源项目旨在提供实时的大规模机器学习/预测分析基础框架目前它实现了一列工程应用常用到的机器学习算法:协同过滤,分类/回归以及聚类。Oryx 通过Apache hadoop来实现对大规模的数据流进行建模。同时可以通过实时的REST API来对建好的模型进行查询,并且有也可以通过API将新数据输入到模型中进行训练。
Oryx 具有以下特点:
- Hadoop 版本跟着 CDH 升级
- 将推荐引擎分为 Serving Layer 和 Computing Layer,隔离出 Serving Layer 让扩展变得很容易
- 同时支持推荐、聚类、分类的机器学习
- 数据引入了 Generation 的概念,提供了很好的增量补充数据的支持
目前Oryx release的版本是Oryx1.0,而Oryx2.0也正在孵化当中。相较于1.0版本,Oryx2.0更好的实现了lambda架构,使得各个层之间可复用性更强。实现了比1更多的机器学习算法(1.0只实现了,ALS协同过滤,随机森林,以及K-means++算法)同时2.0版本还引入更新的Spark和Streaming技术。
安装Oryx
Oryx 的安装需要运行环境,以及Hadoop2.3或以后的运行环境,这里我们悬着Cloudera公司的CDH5发行的hadoop版本,也是官方推荐的版本。CDH5的安装,请参见上一篇文章。
Oryx的Server层和Computation层都是独立的Jar包oryx-serving-x.y.z.jar和oryx-computation-x.y.z.jar,只需要用java命令单独的运行这两个Jar包即可。需要注意的是这里的两个jar包不是在hadoop jar命令中运行,只是在长期跑的服务器程序。
跑Oryx例子stepBystep
Orxy官方的项目提供了3个机器学习的例子,分别是用协同过滤做推荐,用随机森林做分类,用K-means++做聚类。在运行这些例子之前我们先要做一下准备工作。
- 已经建立了CDH5 或者Hadoop2.0+的环境,如果没有请参考这里
- 运行
git -clone https://github.com/cloudera/oryx.git,将项目下载到本地的机子上并用unzip命令解压,并cd到该目录下。 这样我们就准备好了,开始跑第一个例子吧。
例1.建立一个简单的推荐系统
第一个例子采用了交替最小二乘的算法ALS (alternating least squares)是对audioscrobbler数据库(last.fm的音乐数据)的一些样本建立推荐系统。为了建立这个系统,ALS-Modle要求的输入的原始数据格式必须是user,item或者是user,item,strength。每列的数据必须用,隔开,前两列可以是任何数据类型(数字和非数字都可以),最后一列是可选的,但必须是数字类型。
我们看一眼audioscrobbler数据库的数据。
1000002,"A Perfect Circle",144
1000002,"Aerosmith",314
1000002,"Metallica",329
1000002,"Counting Crows",157
1000002,"Dire Straits",125
1000002,"Free",155
1000002,"Guns N' Roses",236
1000002,"Goo Goo Dolls",119
1000002,"Michael Jackson",104
1000002,"Barenaked Ladies",115
第一列为用户ID,第二列为歌手的名字,第三列为喜爱度。 正常情况下会把数据放在hadoop下跑,我们可以通过下面的指令把下载下来的数据库存放到hdfs上:
hadoop fs -mkdir -p /user/oryx/example/00000/inbound
hadoop fs -copyFromLocal [data file] /user/oryx/example/00000/inbound/
这里我们只在本地做一下实验,将数据拷贝到/tmp/oryx/example:
mkdir -p /tmp/oryx/example1/00000/inbound
cp audioscrobbler-sample.csv.gz /tmp/oryx/example/00000/inbound/
为了运行Serving层和computation层,我们必须定义一个配置文件,来告诉程序如何运行。配置文件详细的说明可以在common/src/main/resources/reference.conf下查看。我们这的配置例子如下:
model=${als-model}
model.instance-dir=/tmp/oryx/example1
model.local-computation=true
model.local-data=true
model.features=25
model.lambda=0.065
我们可以用vim oryx-example1.conf新建一个配置文件将内容填入。
接着我们便可以运行计算层和服务层了。可以看到model类型为ALS-model,instance-dir,设定了存放数据的地址。
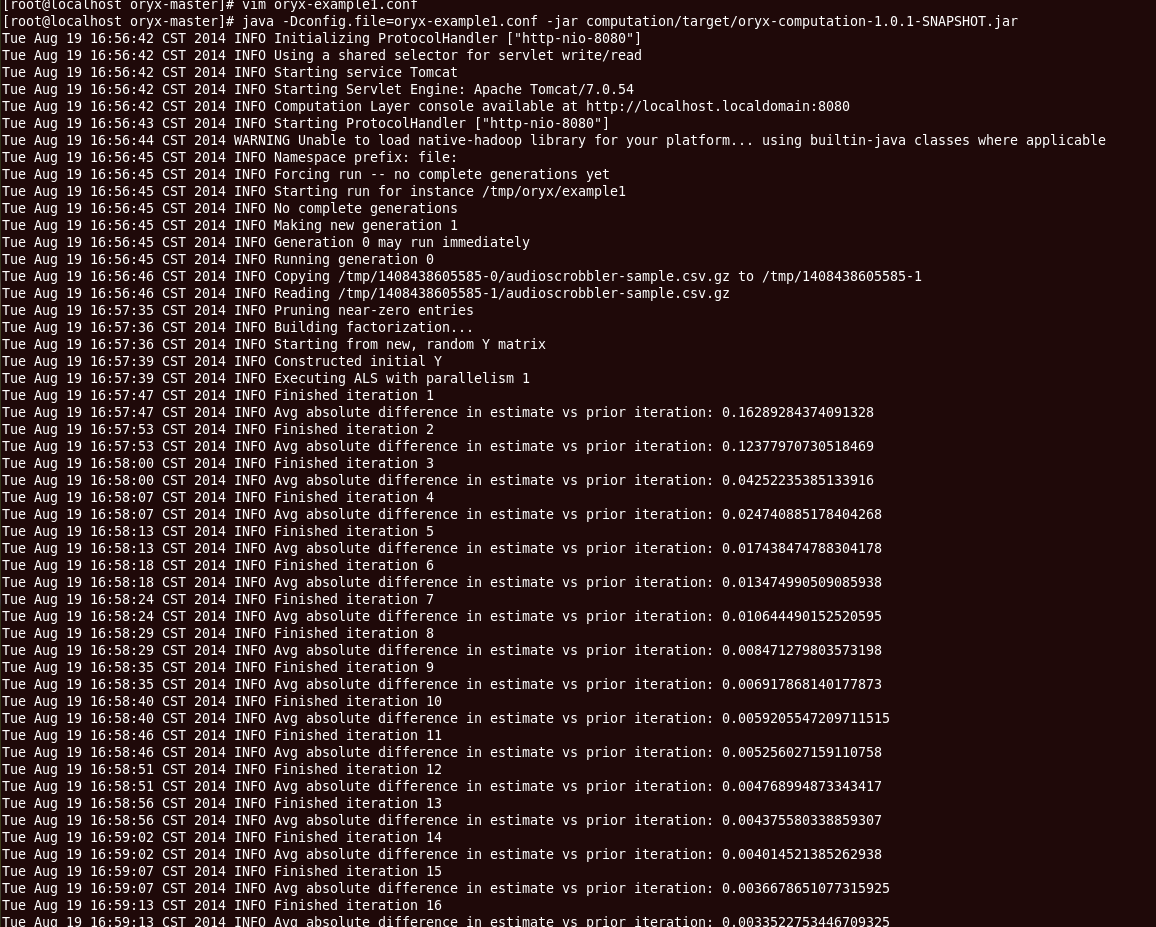
java -Dconfig.file=oryx-example1.conf -jar computation/target/oryx-computation-1.0.1-SNAPSHOT.jar
我们可以看到程序的运行日志,看到从读取数据到不停跌代进行矩阵分解的整个过程
 接着我们运行serving层:
接着我们运行serving层:
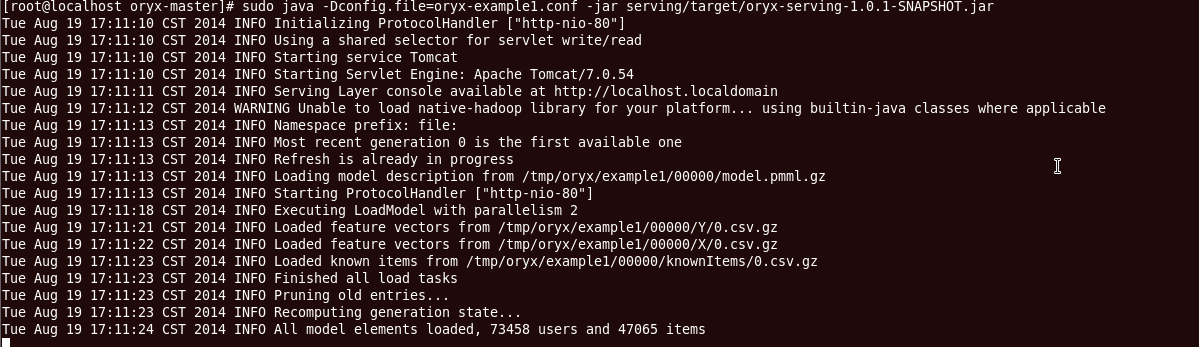
sudo java -Dconfig.file=oryx-example1.conf -jar serving/target/oryx-serving-1.0.1-SNAPSHOT.jar
serving 层开启了Tomcat网络服务,并且加载了模型中的元素。日志如下:
 我们还可以在浏览器中查看运行的结果,在浏览器上输入
我们还可以在浏览器中查看运行的结果,在浏览器上输入http:\\localhost,我们便可以显示的看到所有oryx提供的API。
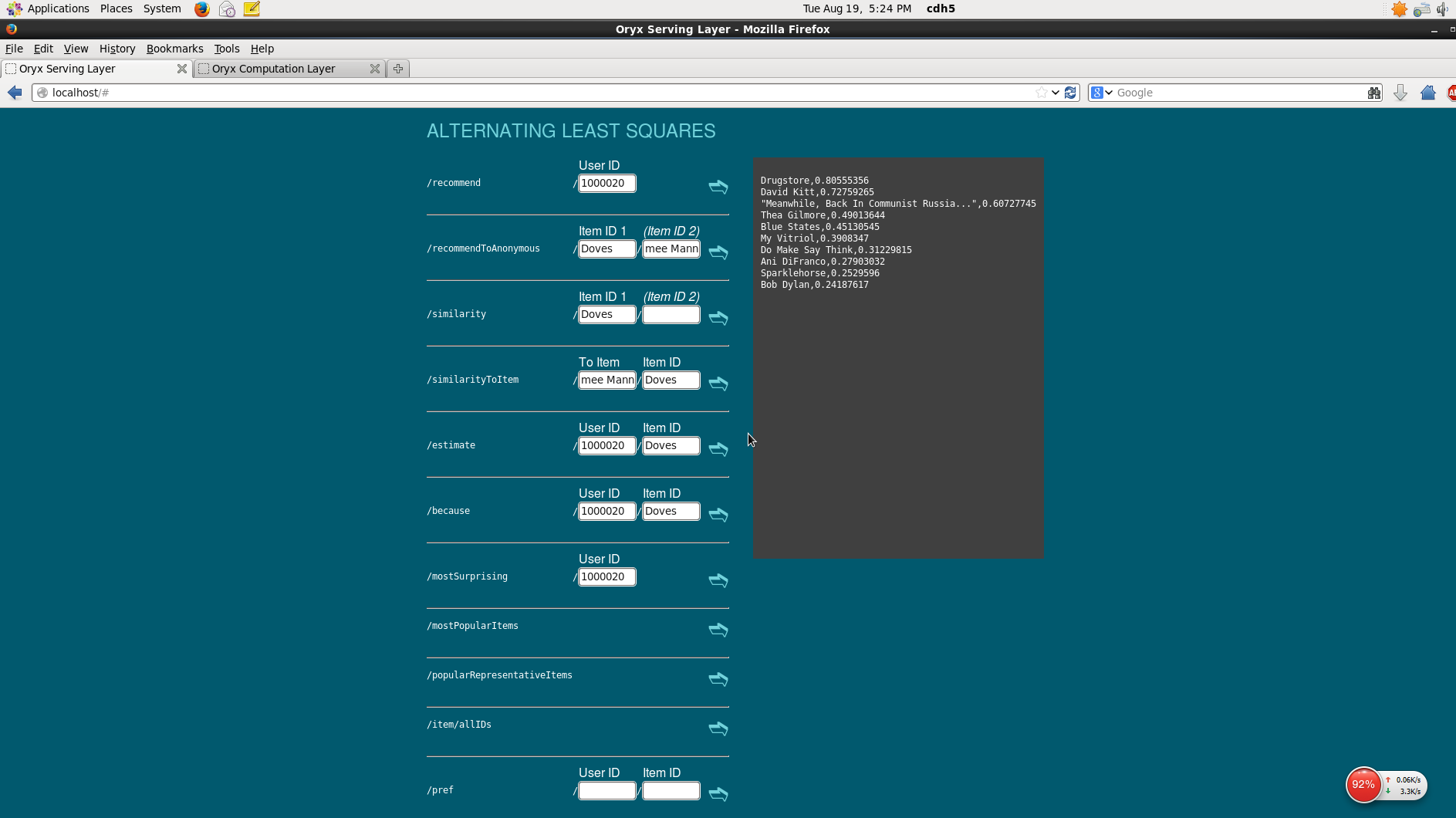 包括对某一用户做推荐,物品间的相似度,用户对某个item的偏好,最受欢迎Item等等,甚至可以在原来数据的基础上添加数据再对这些数据进行推荐,非常方便。
在浏览器中输入
包括对某一用户做推荐,物品间的相似度,用户对某个item的偏好,最受欢迎Item等等,甚至可以在原来数据的基础上添加数据再对这些数据进行推荐,非常方便。
在浏览器中输入http:\\localhost:8080可以查看计算时候的资源消耗等等一系列属性,由于我们是在本地跑,所以上面没有数据显示。
至此我们的第一个实验就做完了。
例2.利用随机森林算法做分类
这里随机森林算法是机器学习中常用的算法,有关它的介绍可以看这里。例子二对某一地区的森林覆盖类型做分类的例子。数据集采用了UCL repository。该数据集记录了581012个样本地区的54个特征,包括海拔,坡度,到最近水域的垂直距离和水平距离,土壤类型等等。更详细的描述可以参见covtype.info文件。
它的一条样本是这个样子的:
2596,51,3,258,0,510,221,232,148,6279,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,5
跟例子1类似,我们同意需要配置文件orxy-example2.conf,在里面输入:
model=${rdf-model}
model.instance-dir=/tmp/oryx/example2
model.local-computation=true
model.local-data=true
inbound.numeric-columns=[0,1,2,3,4,5,6,7,8,9]
inbound.target-column=54
inbound.column-names=["Elevation", "Aspect", "Slope", "Horizontal_Distance_To_Hydrology",
"Vertical_Distance_To_Hydrology", "Horizontal_Distance_To_Roadways", "Hillshade_9am", "Hillshade_Noon",
"Hillshade_3pm", "Horizontal_Distance_To_Fire_Points", "Wilderness_Area1", "Wilderness_Area2",
"Wilderness_Area3", "Wilderness_Area4", "Soil_Type1", "Soil_Type2", "Soil_Type3", "Soil_Type4",
"Soil_Type5", "Soil_Type6", "Soil_Type7", "Soil_Type8", "Soil_Type9", "Soil_Type10", "Soil_Type11",
"Soil_Type12", "Soil_Type13", "Soil_Type14", "Soil_Type15", "Soil_Type16", "Soil_Type17", "Soil_Type18",
"Soil_Type19", "Soil_Type20", "Soil_Type21", "Soil_Type22", "Soil_Type23", "Soil_Type24", "Soil_Type25",
"Soil_Type26", "Soil_Type27", "Soil_Type28", "Soil_Type29", "Soil_Type30", "Soil_Type31", "Soil_Type32",
"Soil_Type33", "Soil_Type34", "Soil_Type35", "Soil_Type36", "Soil_Type37", "Soil_Type38", "Soil_Type39",
"Soil_Type40", "Cover_Type"]
这里模型选择是rdf-model,同意定义了数据的一些格式0~9为数字,label列是滴54列,以及各个列的名名称。
然后我们把下载到的文件拷贝的/tmp/oryx/example2/00000/inbound下,按上例的方法运行serving层和computation层。只是配置文件做改变。
java -Dconfig.file=oryx-example2.conf -jar
computation/target/oryx-computation-1.0.1-SNAPSHOT.jar
sudo java -Dconfig.file=oryx-example2.conf -jar serving/target/oryx-serving-1.0.1-SNAPSHOT.jar
计算层的时间会比较长,需要较长时间等待。相信在集群上跑回好很多。
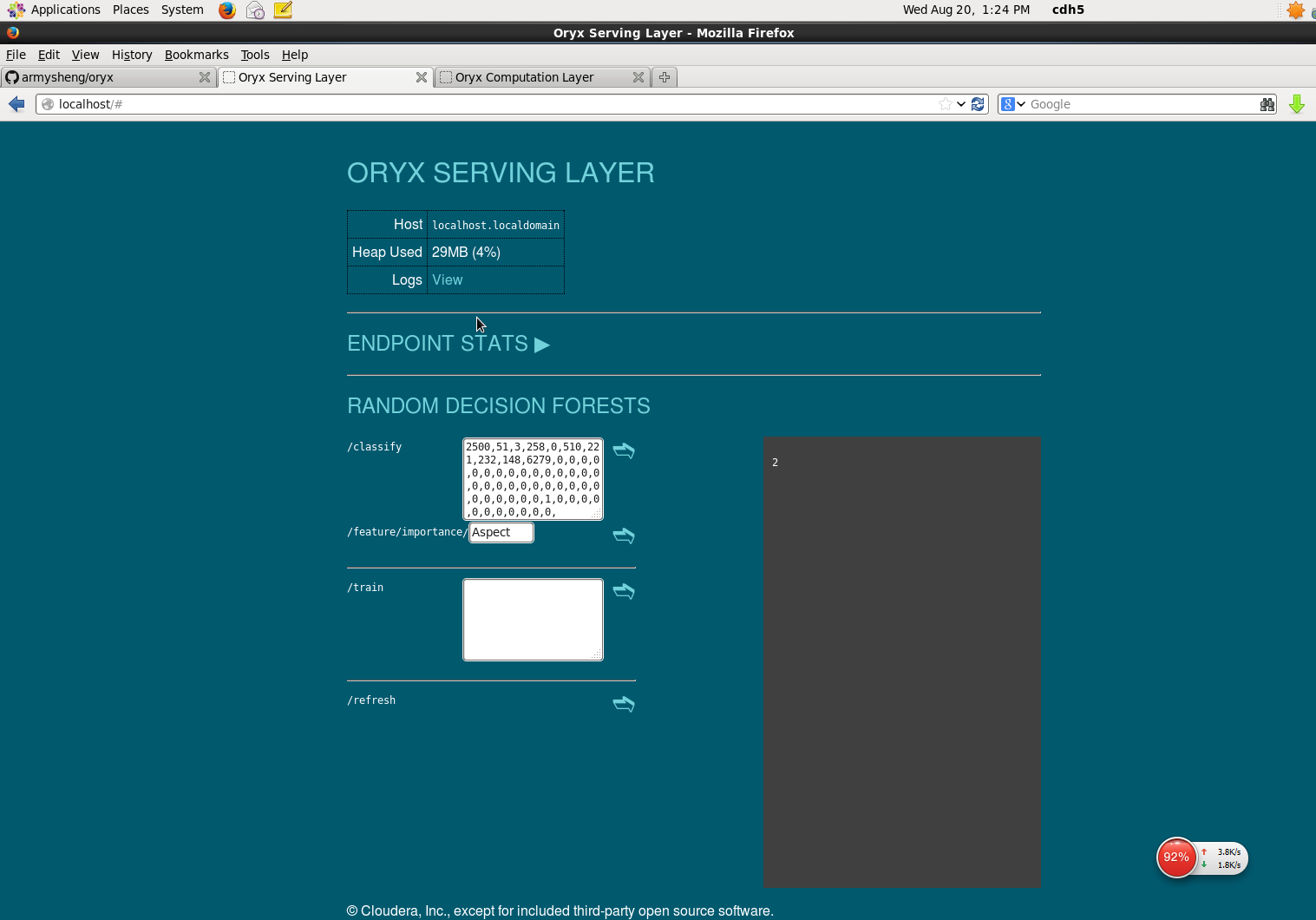 我们可以在
我们可以在/classify栏里手动的输入一个样本:
2500,51,3,258,0,510,221,232,148,6279,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,
进行判别,得到分类结果。
例3.使用K-means++算法聚类
oryx的聚类算法采用了Scalable K-Means++算法。数据集使用KDD Cup 1999的数据,kddcup.data_10_percent.gz A 10% subset. (2.1M; 75M Uncompressed)。
由于内存较小,在用-Xmx 1024m分配了1G内存后,运行过程还是出现了OutofMemoryError。所以在本地单机没法进行,serve层开放的API如下:
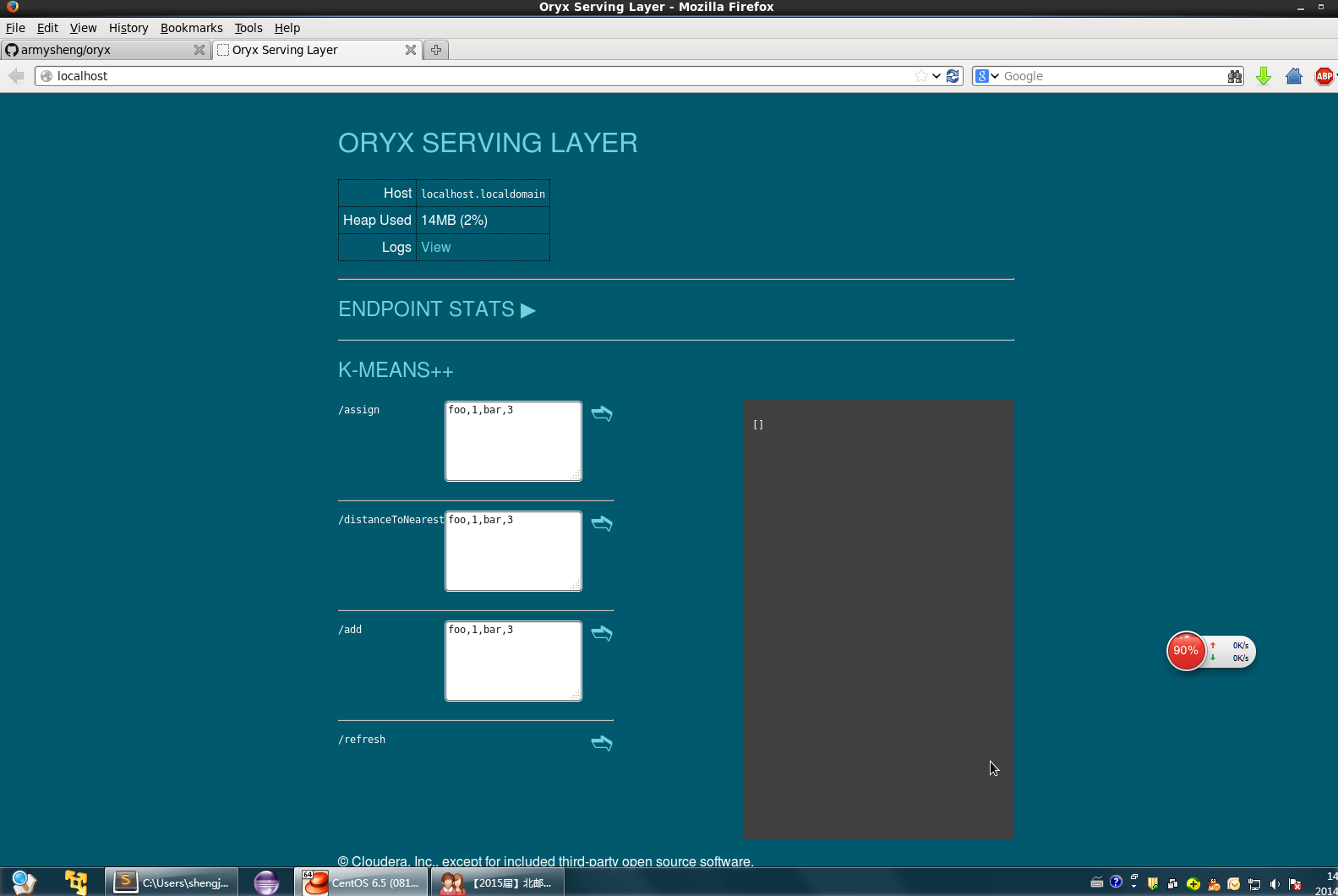 可以使用
可以使用/assign对新样本进行聚类。
0,tcp,http,SF,259,14420,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,1,1,0.00,0.00,0.00,0.00,1.00,0.00,0.00,11,97,1.00,0.00,0.09,0.08,0.00,0.00,0.00,0.00
总结
至此我们就初步体验了oryx这个开源的大规模机器学习框架,虽然目前oryx实现的算法比较少,但是可以看到他的lamda架构,提供Rest API,generation概念,以及对Hadoop乃至Spark的适配,必将使得它在未来推荐系统领域占领一席之地。

